Fairness aware AutoML on binary classification task¶
Please run the example script to get example results for binary classification task on Adult dataset with sex as sensitive feature.
python examples/scripts/binary_classfier_adult_fairness.py
Please notice that you don't have to specify privileged_groups and underprivileged_groups - AutoML will detect them automatically based on provided data.
Possible modifications¶
Add more algorithms¶
In the example script only Xgboost is used. Fairness aware training supports all algorithms in the AutoML. You can extend list of the algorithms in the AutoML constructor:
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_openml
from supervised.automl import AutoML
data = fetch_openml(data_id=1590, as_frame=True)
X = data.data
y = data.target
sensitive_features = X[["sex"]]
X_train, X_test, y_train, y_test, S_train, S_test = train_test_split(
X, y, sensitive_features, stratify=y, test_size=0.75, random_state=42
)
# you can add more algorithms
automl = AutoML(
algorithms=[
"Xgboost",
"CatBoost",
"LightGBM",
"Random Forest"
],
train_ensemble=False,
fairness_metric="demographic_parity_ratio",
fairness_threshold=0.8,
privileged_groups = [{"sex": "Male"}],
underprivileged_groups = [{"sex": "Female"}],
)
automl.fit(X_train, y_train, sensitive_features=S_train)
You should get much more models in the leaderboard:
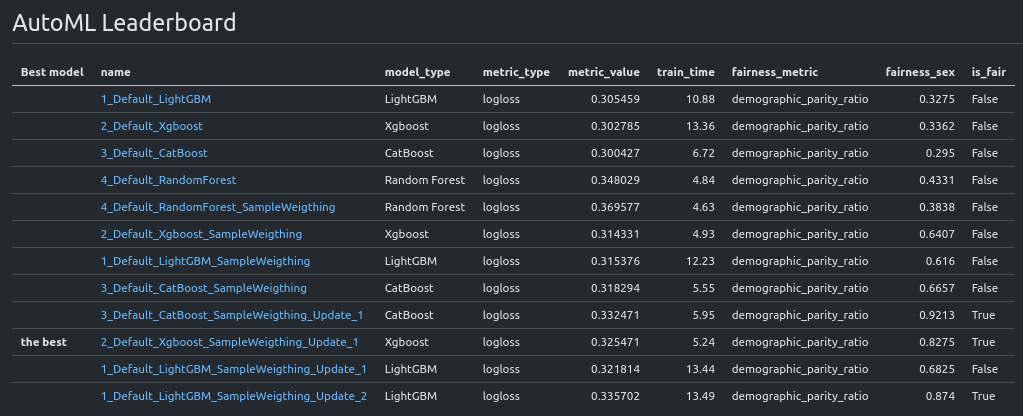
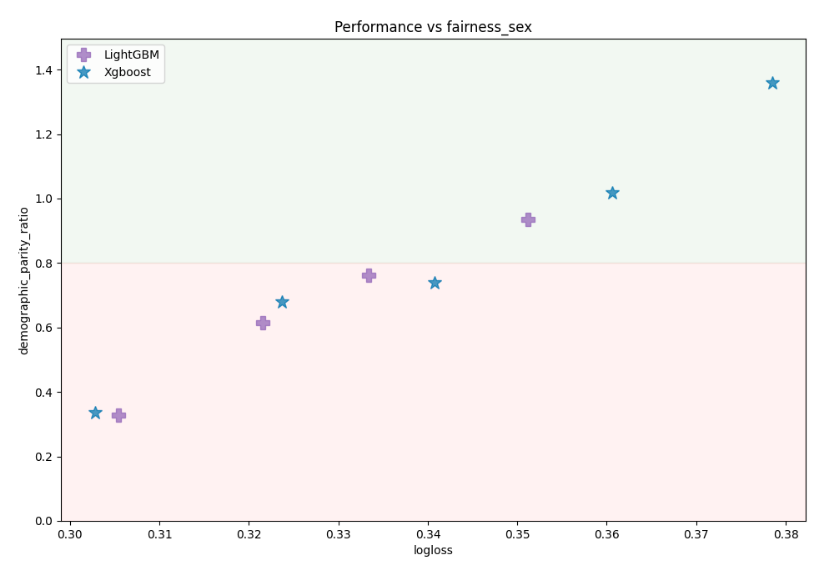
Performance plot vs fairness metric:
Change mode¶
By default there is Explain mode used for AutoML training. You can change mode to check more ML models. The Compete mode should gives you the best performance.
Multiple sensitive features¶
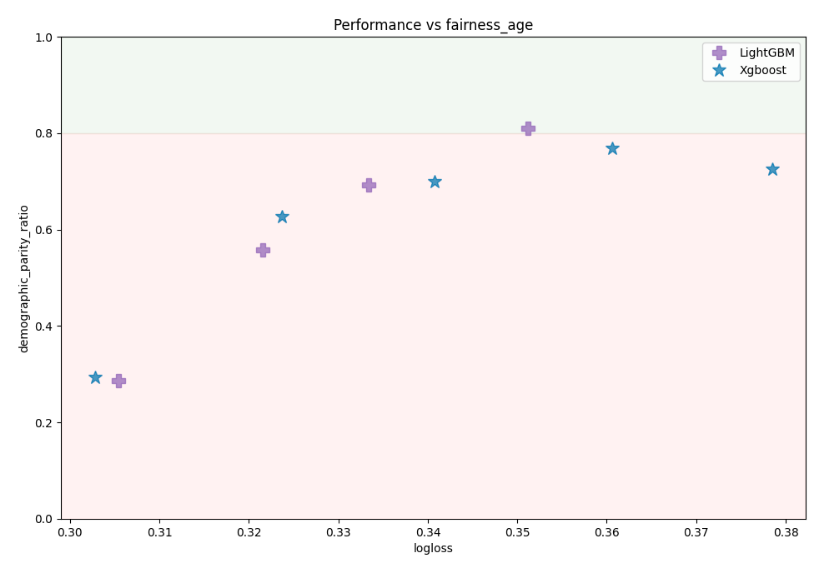
You can use multiple sensitive features (not only one!). Below is the example that sets two sensitive features: sex and age. Please notice that age is continuous feature - AutoML will automatically convert it to binary feature with equal size bins.
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_openml
from supervised.automl import AutoML
data = fetch_openml(data_id=1590, as_frame=True)
X = data.data
y = data.target
#
# multiple sensitive features
#
sensitive_features = X[["sex", "age"]]
X_train, X_test, y_train, y_test, S_train, S_test = train_test_split(
X, y, sensitive_features, stratify=y, test_size=0.75, random_state=42
)
automl = AutoML(
algorithms=[
"Xgboost",
"LightGBM"
],
train_ensemble=False,
fairness_metric="demographic_parity_ratio",
fairness_threshold=0.8,
privileged_groups = [{"sex": "Male"}],
underprivileged_groups = [{"sex": "Female"}],
)
automl.fit(X_train, y_train, sensitive_features=S_train)
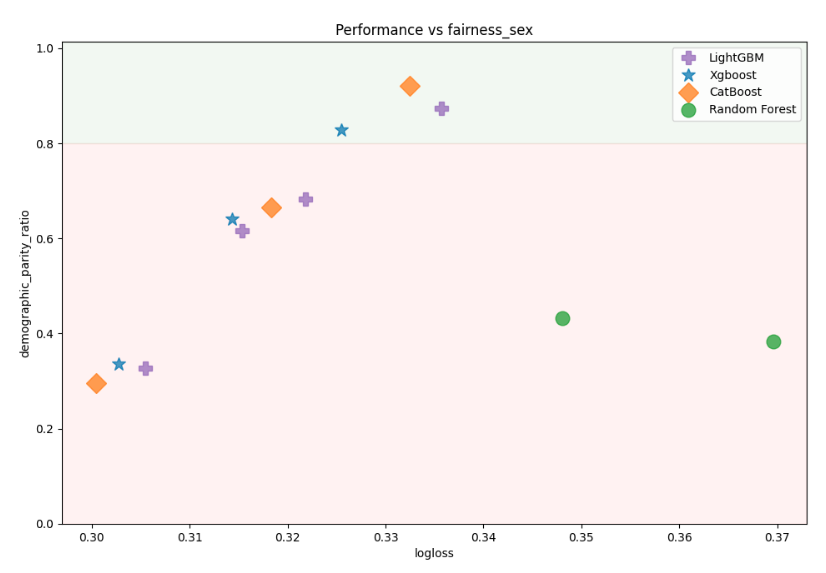
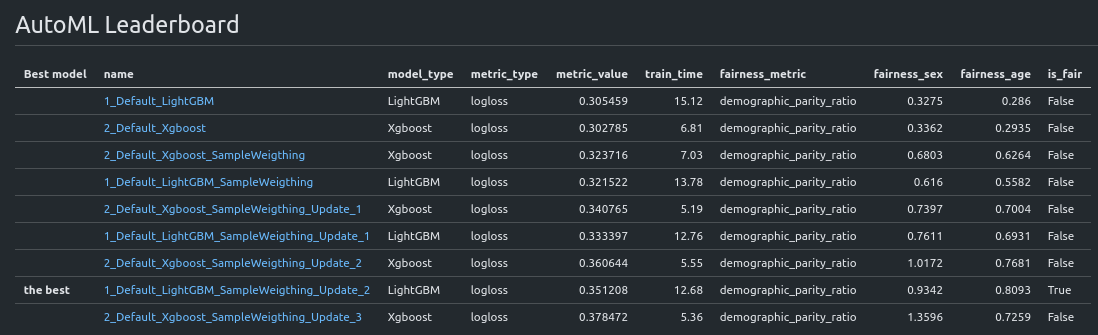
AutoML leaderboard for training with multiple sensitive features. Please notice that fairness metric is reported for each sensitive feature:
Models performance (logloss) vs fairness metric on sex feature:
Models performance (logloss) vs fairness metric on age feature: