How does ensemble stacking work?¶
Before introducing ensemble stacking, we should talk about the steps of Ensemble and Stack first:
1. Ensemble¶
After all Level-0 models are trained step by step (like simple_algorithms, default_algorithms, not_so_random, golden_features, insert_random_feature, feature_selection, etc.), it will start to process the Ensemble step.
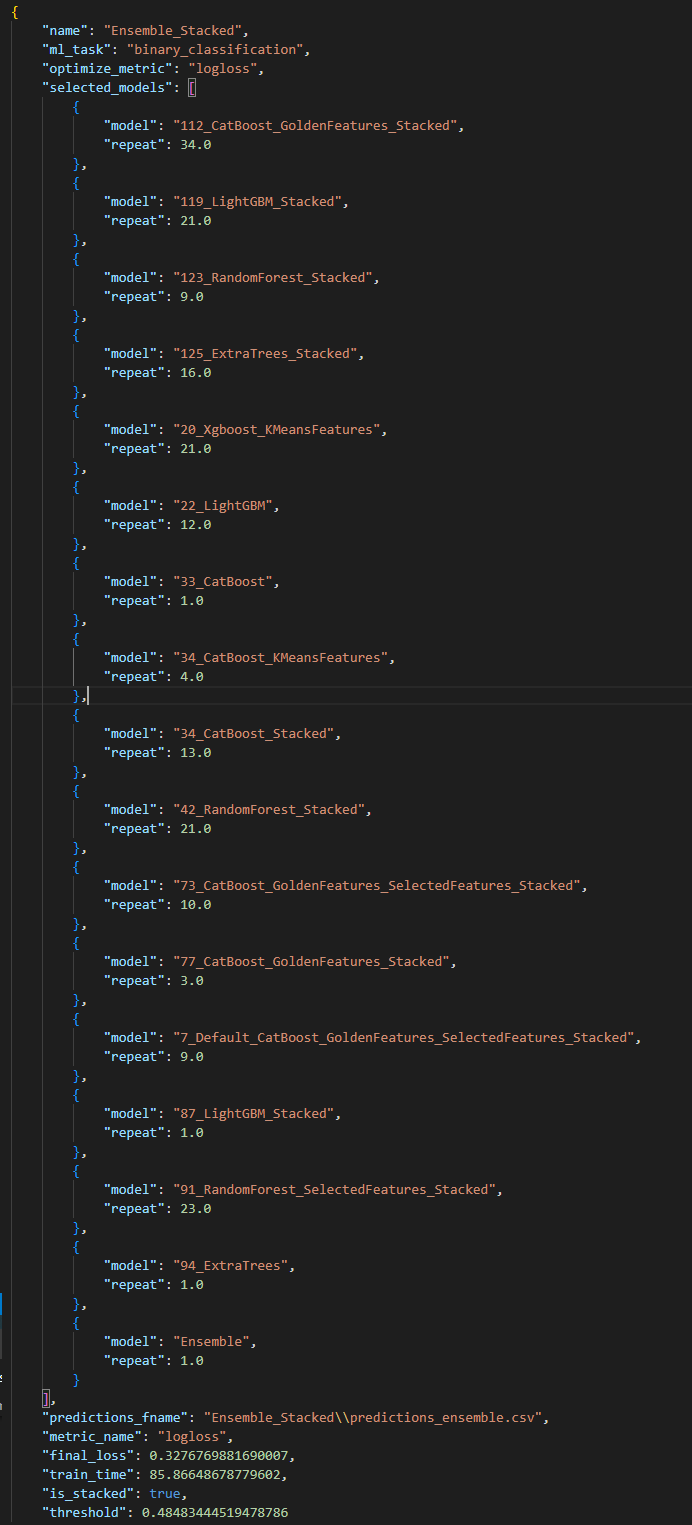
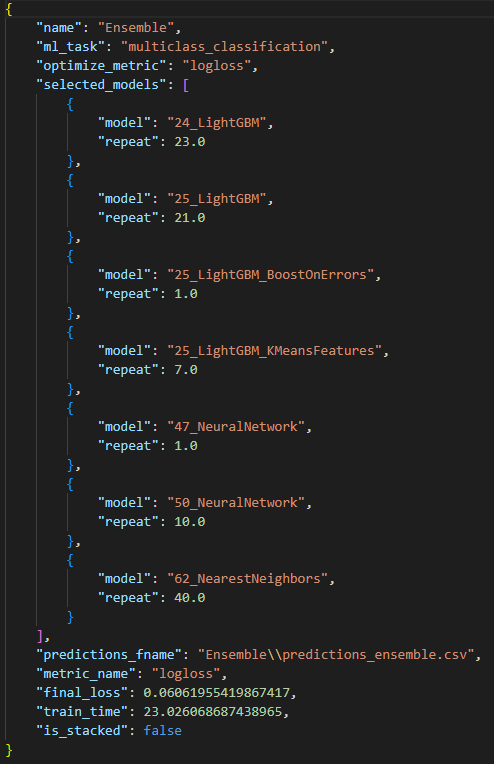
In this process, the weight values according to the all Level-0 model will be calculated and become Ensemble model. The final selected Level-0 model and their weight values will list in the ensemble.json under ensemble folder (example file showed as following , The “repeat” here means the weight value of each selected model)
2. Stack¶
The Stack process flow showed as below:
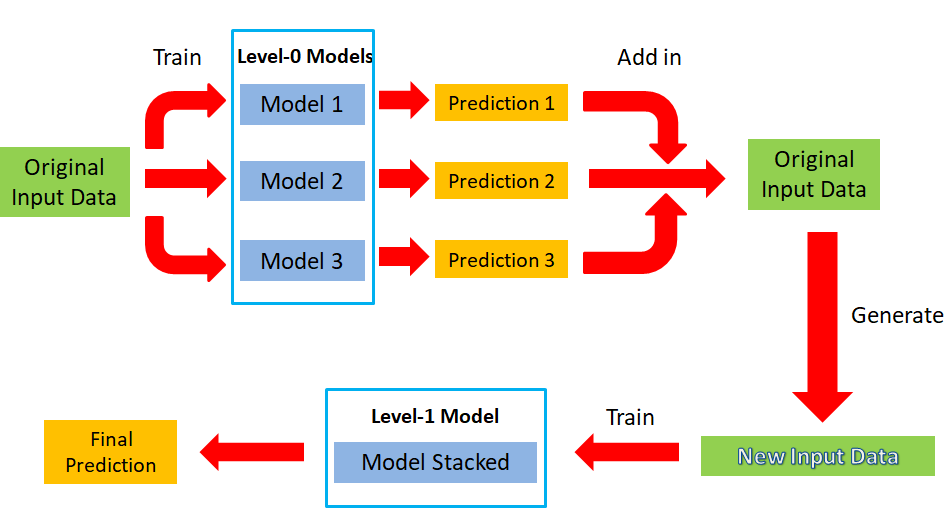
The original input data is used to train several models of Level-0, and the prediction results of the models are added to the original data then generate new input data, which will be used to train the Stacked Model of Level-1 and obtain the final prediction result.
3. Ensemble stacking¶
Ensemble stacking means to ensemble the above-mentioned Level-0 and Level-1 models with different weight values and predict final results. The final selected Level-0 and Level-1 models and their weight values will list in the ensemble.json file which under the ensemble_stacked folder. (as shown in the figure below, repeat here means the weight value)